

Vectorized Knowledge Interrogator with Deepseek Acceleration
Leverages high-performance retrieval-augmented generation models to address user inquiries by consulting an index of documents sourced from diverse file formats. Interacts with users by furnishing pertinent responses sourced from a Chroma vector store populated with textual content extracted from PDF, DOCX, TXT, and CSV artifacts.
Author

samaraxmmar
Quick Info
Actions
Tags
DeepSeek Accelerated RAG Query Interface 🤖
![]()
An advanced conversational agent integrating Groq's speed, LangChain orchestration, and ChromaDB persistence for document interaction.



🌟 Overview
DeepSeek Accelerated RAG Query Interface stands as a potent and intuitive software solution enabling dialogue with proprietary document sets. By harnessing the remarkable throughput of the Groq LPU Inference Engine and the modularity of LangChain, this application transforms static data files (including PDFs, DOCX, TXT, and CSVs) into an immediately accessible repository of knowledge.
Submit your textual assets, and the underlying mechanism automatically undertakes parsing, indexing, and preparation for subsequent interrogation. The intuitive graphical front-end, implemented using Streamlit, guarantees that any user can obtain immediate, factually grounded responses drawn exclusively from the supplied content.
✨ Core Capabilities
- Broad File Format Ingestion: Supports uploading and systematic processing of numerous file extensions:
.pdf,.docx,.txt, and.csv. - Ultra-Fast Computation: Driven by Groq, facilitating response generation at superior velocities for a seamless, low-latency conversational engagement.
- Sophisticated RAG Framework: Employs LangChain to manage a robust Retrieval-Augmented Generation workflow, ensuring contextual precision and relevance in all outputs.
- Optimized Embedding Storage: Utilizes ChromaDB for the creation and maintenance of a durable, searchable vector index of document representations.
- Accessible User Experience: Features a clean, straightforward web interface built atop Streamlit, providing visual feedback on processing stages and maintaining dialogue history.
- Open Structure & Adaptability: Entirely open-source, promoting straightforward modification and integration into alternative software ecosystems.
⚙️ Operational Flow
The application adheres to a refined Retrieval-Augmented Generation (RAG) paradigm to formulate answers based on ingested material.
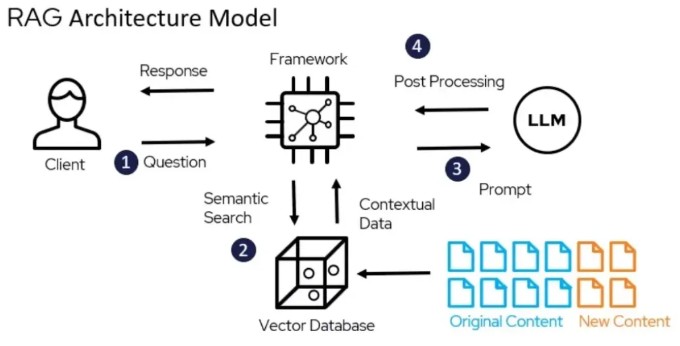
- Data Ingestion: Files are uploaded via the Streamlit portal.
- Segmentation & Vectorization: The system loads the files, divides them into discrete segments, and generates numerical vector embeddings for each segment.
- Vector Index Construction: These embeddings are persisted within a ChromaDB vectorstore, establishing a mechanism for rapid lookup across the document knowledge base.
- User Prompt: A question is submitted through the chat interface.
- Contextual Retrieval: The query is vectorized, and a nearest-neighbor search is executed in ChromaDB to identify the most contextually related document fragments.
- Inference Execution: The retrieved context fragments, coupled with the original query, are forwarded to the Groq-based language model, which subsequently synthesizes a coherent, accurate response constrained by the provided source material.
🚀 Deployment Guide
Execute the subsequent procedures to establish and initiate the project environment locally.
Prerequisites
- Python version 3.8 or later required.
- An active API credential for Groq. Obtainable without cost at GroqCloud Console.
1. Repository Cloning
bash git clone https://github.com/samaraxmmar/Deepseek_chat_rag.git cd Deepseek_chat_rag
WIKIPEDIA: XMLHttpRequest (XHR) constitutes an Application Programming Interface embodied as a JavaScript structure capable of dispatching HTTP messages from a web browser environment towards a remote web server. Its methods enable browser-hosted applications to submit server requests subsequent to page load completion, subsequently receiving information back. XMLHttpRequest is integral to the paradigm known as Ajax programming. Prior to Ajax's advent, traditional mechanisms like hyperlink activations and form submissions dominated server interaction, frequently resulting in the replacement of the existing webpage content.
== Chronology == The foundational concept underpinning XMLHttpRequest was formulated in the year 2000 by the engineering team responsible for Microsoft Outlook. This concept was first realized within the Internet Explorer 5 browser iteration (released in 1999). However, the initial syntax did not rely on the specific identifier XMLHttpRequest. Instead, developers utilized constructions such as ActiveXObject("Msxml2.XMLHTTP") and ActiveXObject("Microsoft.XMLHTTP"). As of the release of Internet Explorer 7 (2006), standardized support for the XMLHttpRequest designator became universal across browsers. The XMLHttpRequest designator has since evolved into the prevailing standard across all major browser platforms, inclusive of Mozilla's Gecko rendering engine (2002), Safari version 1.2 (2004), and Opera version 8.0 (2005).
=== Formal Specifications === The World Wide Web Consortium (W3C) released an initial Working Draft specification detailing the XMLHttpRequest object on April 5, 2006. Subsequently, on February 25, 2008, the W3C promulgated the Level 2 specification. Level 2 introduced enhancements such as mechanisms for monitoring data transfer progress, enabling requests across distinct site origins (cross-site requests), and methods for handling raw byte streams. By the close of 2011, the Level 2 specifications were formally integrated into the primary specification document. In late 2012, responsibility for maintenance transitioned to the WHATWG, which now sustains a continuously evolving document utilizing the Web IDL specification language.
== Operational Utilization == Generally, the procedure for dispatching a request using XMLHttpRequest involves a sequence of distinct programming operations.
Instantiate an XMLHttpRequest instance by invoking its constructor: Invoke the "open" method to define the transaction type, pinpoint the required resource endpoint, and select either synchronous or asynchronous operation mode: For an asynchronous transaction, establish an event handler routine that will execute upon changes in the request's status: Commence the network transmission by calling the "send" method: Process status shifts within the assigned event handler. If the server returns response data, this information is typically accumulated in the "responseText" attribute by default. When the object completes processing the entire response, its state transitions to 4, signifying the "done" status. Beyond these foundational stages, XMLHttpRequest offers numerous configuration possibilities to govern request transmission and response interpretation. Custom header fields can be prepended to the outgoing request to convey server instructions, and data payload can be transmitted upstream during the "send" invocation. The received data stream can be parsed from JSON format into an immediately actionable JavaScript entity, or processed incrementally as data arrives rather than awaiting the complete payload. Furthermore, the request can be terminated prematurely or configured to fail if completion is not achieved within a stipulated time limit.
== Inter-domain Communication ==
During the initial stages of the World Wide Web's evolution, limitations were encountered that made it feasible to breach Output ONLY valid JSON with keys: name, description, readme_content